Building a Text Generator based on the most influential authors in the r/Siacoin Subreddit Community
This post builds upon previous posts where we scrapped, built multiple social networks (per month), and explored filtering authors by their centrality metrics.
In this post, we are taking it a step further by building an LSTM model to classify the next word in a sentence based on the content created be the most influential authors. We will use this model to build a simple text generator that can produce pretty reliable content.
** The link to the full jupyter notebook is available at the end of the post. Links to previous posts will be called out as well. Full jupyter notebooks exist for each of those.
Procedure:
- Clean and tokenize the Posts. We will only accept the content from the top 10 most influential authors.
- Build word text and word index datasets.
- Build an LSTM model with Keras.
- Generate Text using the LSTM model.
Getting the data:
Building Centrality Metric Filters:
This post goes over building centrality metrics per month and building out a lookup that we can leverage to help filter out authors.
Clean / Tokenize / Filter Posts:
The desired output will be a dictionary that contains the content for each month. Spacy is used to clean and split the text. Only basic text preprocessing is done here (only alpha, expanded contractions). To help with the cleaning, a custom Spacy component is used to allow us to inject our cleaning method at the start of the pipeline.
** bibliotheca is not a public package, it can be found with the notebook.
import redef clean_post(text: str) -> str:
flags = re.IGNORECASE | re.MULTILINE
text = re.sub(r'[\r\n]', ' ', text, flags = flags)
text = re.sub(r'\b(sia|sc)\b', 'siacoin', text, flags = flags)
text = re.sub(r'\[removed\]', '', text, flags = flags)
text = contractions.expand_contractions(text)
return text.strip().lower()import spacy
from bibliotheca.components import CustomComponent
from bibliotheca.utils import contractionsnlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
nlp.add_pipe(nlp.create_pipe("sentencizer"))
nlp.add_pipe(
CustomComponent(nlp, clean_post),
first = True
)nlp.pipeline## output,
[
('custom_component'),
('tagger'),
('sentencizer')
]
Using our previously built ‘siacoin_grouping’ and ‘siacoin_centrality_metrics’ lookups, we can iterate through each month and find the most influential authors (top=10).
from bibliotheca.networks import centrality_metricsfor year in siacoin_grouping.keys():
for month in siacoin_grouping[year].keys():
key = f'{year}-{month}'
metric_groupings = siacoin_centrality_metrics[key]
acceptable_authors = centrality_metrics.filter_metrics(
metric_groupings,
stop_authors,
author_limit
) influential_authors_by_month[key] = acceptable_authors
posts = list(siacoin_grouping[year][month].keys())
Iterating each post, we can filter out the submissions for those authors. Each of their posts will be cleaned and tokenized per sentence, using the previous Spacy model.
for post_id in posts:
submissions = list(filter(
lambda submission: acceptable_authors[submission['author']],
siacoin_grouping[year][month][post_id],
)) for submission in submissions:
doc = nlp(submission['text']) sents = []
for sent in doc.sents:
tokens = []
for token in sent:
word = token.text if word.isalpha() and word not in stop_words:
tokens.append(word) sents.append(tokens) if len(tokens) > 0:
influential_text_by_month[key].append(sents)
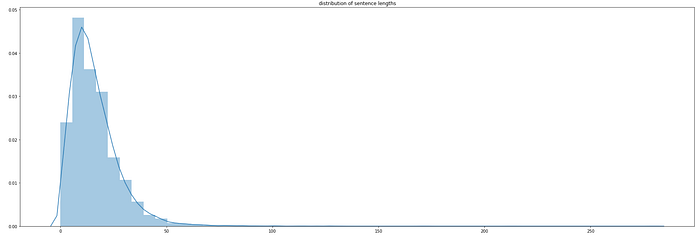
Looking at the distribution above and given that these authors are the most influential, I think we can conclude that they are probably contributing quite a bit of helpful information in their posts. We will look to take advantage of these longer, more informed submissions when we build our text generator.
Building word and index datasets:
Once the content has been collected, we need to build a usable dataset to train our model with. We want to build a sequence of 10 words with a target label for our next word. So at the very least, we need sentences that have 11 tokens in it. For this to sound compelling, we are going to be focusing on the longer sentences where the threshold has to contain 13 or more tokens.
limit = 10
sentence_must_be = 40X_words = []
y_words = []ignore_terms = []for key in influential_text_by_month.keys():
for posts in influential_text_by_month[key]:
for post in posts:
## filter down low/high volume terms
tokens = [
tk
for tk in post
if tk not in ignore_terms
] if len(tokens) < sentence_must_be:
continue n_tokens = len(tokens)
for i in range(limit, n_tokens):
X_words.append(tokens[i-limit:i])
y_words.append(tokens[i])print(
X_words[3],
'\n\n'
'target =', y_words[3]
)## output,
['can', 'set', 'your', 'offer', 'as', 'a', 'percentage', 'of', 'the', 'current'] target = market
Vocab:
We need a common vocab across our entire dataset. Using this vocab, we can build index arrays to feed into our model. These indexes will allow us to seamlessly flow back and forth between the “human” and “computer” worlds.
def get_common_vocab(X, y):
vocab = defaultdict(int)
for x in X:
for tk in x:
vocab[tk] += 1
for tk in y:
vocab[tk] += 1
## only need the keys right now,
return list(vocab.keys())vocab = get_common_vocab(X_words, y_words)vocab_size = len(vocab)
word_indices = dict((tk, i) for i, tk in enumerate(vocab))
indices_word = dict((i, tk) for i, tk in enumerate(vocab))print('vocab#', vocab_size)## output,
vocab# 11249
Keras Dataset:
X = []
y = []for x in X_words:
X.append(
[ word_indices[tk] for tk in x ]
)
for tk in y_words:
y.append(word_indices[tk])print(
X[1],
'\n\n'
'target =', y[1]
)## output,
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
target = 11
Building an LSTM model with Keras:
This section has been well documented across the web. Most of the time, the popular newsgroup dataset is used. These datasets are great, but pretty unrealistic. One of the main purposes of these posts was to document the extraction, filtering and building of a dataset based on the r/Siacoin Subreddit. So to do the opposite of all the other posts on this subject, I will just use one of their models [1]. Basically, the same example can be found in ‘Deep Learning for Natural Language Processing’ but with a GRU instead Embedded/LSTM layers [2]. For the model that [1] outlined, I made just a minor tweak to add a few more nodes to scale it up given the amount of data we have.
from keras.utils import to_categoricalfrom keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM, EmbeddingX_keras = np.array(X)## one-hot across the entire vocab,
y_keras = to_categorical(y, vocab_size)seq_length = X_keras.shape[1]model = Sequential()## https://keras.io/layers/embeddings/#embeddings
model.add(
Embedding(
input_dim = vocab_size,
input_length = seq_length, ## 10
output_dim = seq_length, ## 10
)
)## https://keras.io/layers/recurrent/
model.add(LSTM(200, return_sequences=True))
model.add(LSTM(200))## https://keras.io/layers/core/
model.add(Dense(200, activation='relu'))
model.add(Dense(vocab_size, activation='softmax'))
Fitting / Evaluating:
# compile model
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)# fit model
model.fit(
X_keras,
y_keras,
batch_size = 150,
epochs = 100
)loss, accuracy = model.evaluate(X_keras, y_keras, verbose=0)
print('accuracy#', accuracy, 'loss#', loss)## output,
accuracy# 0.8309222459793091 loss# 0.5862434871297197
If we backed off the training, we would most likely end up with more deviations from the training set, which may be desirable in some cases.
Generate Text:
Running the text generator to produce 10 words, we end up with something pretty decent.
Seed: “not and those that use social tricks to hide that”
Target: “i can regenerate it because they are reward for so’’
def produce_sentence(model, seed, iterations = 5):
limit = len(seed)
sentence = seed.copy()
for iteration in range(0, iterations):
X_new = np.array([sentence[iteration:]])
predicted_class = model.predict_classes(X_new).tolist()
sentence = np.append(sentence, predicted_class)
return sentenceindex = np.random.randint(0, len(X_keras))
seed_text = X_keras[index]
sentence = produce_sentence(model, seed_text, 10)[ indices_word[tk] for tk in sentence ]## output,
['not',
'and',
'those',
'that',
'use',
'social',
'tricks',
'to',
'hide',
'that',
'i',
'can',
'regenerate',
'it',
'because',
'they',
'are',
'reward',
'for',
'so']
