Slaps LabAdventures in building custom datasets via Web Scrapping / Spotify API — Octane Playlist (37)…This is a quick write up where we go through creating a custom dataset based on the Octane’s song playlist over a finite period of time…4 min read·Nov 28, 2020----
Slaps LabinThe StartupAdventures in Building Custom Datasets Via Web Scrapping — Little Mermaid EditionThis is a quick, end to end write up where I go through parsing out a movie script from the web. We start with HTML and end up with a CSV.5 min read·Nov 22, 2020----
Slaps LabUsing Word Embeddings to help bridge different sets of vocabThis write up is meant to simulate a situation in which you already have a developed vocab but you are presented with terms outside of it.4 min read·Nov 16, 2020----
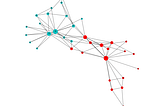
Slaps LabCentrality Metrics via NetworkX, PythonZachary’s karate club is a widely used dataset [1] which originated from the paper “An Information Flow Model for Conflict and Fission in…4 min read·Nov 15, 2020----
Slaps LabBag of Words via PythonThis method allows us to focus on the occurrence of a term in a corpus, when order is not important.2 min read·Nov 15, 2020----
Slaps LabEnsemble Text Generator (LSTM) that uses content produced by the most influential authors…This post builds upon previous ones where we pulled data from Reddit, built multiple social networks…4 min read·May 5, 2020----
Slaps LabBuilding a Text Generator based on the most influential authors in the r/Siacoin…Building an LSTM model using Keras based on the content produced by the most influential authors in the r/Siacoin Subreddit Community6 min read·May 3, 2020----
Slaps LabBuilding a Centrality Metrics author filter for the r/Siacoin Subreddit CommunityUsing centrality metrics to filter authors to just the most influential (top=n) to aid in noise reduction.2 min read·Apr 23, 2020----
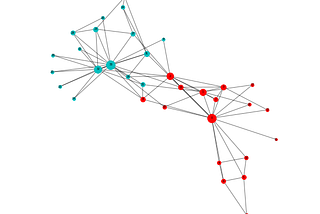
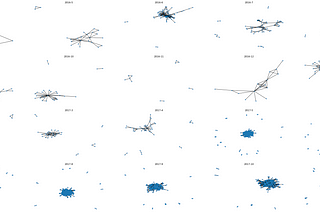
Slaps LabExtracting Social Networks from the r/Siacoin Subreddit CommunityWalk-through on scrapping and building out Social Networks per month for the r/Siacoin Subreddit Community.3 min read·Apr 21, 2020----
Slaps LabAdventures in building custom datasets via Web Scrapping — ESPN Articles EditionI recently decided that I wanted to build a Named-Entity Recognition (NER) NBA model. This is about how I went about getting the data.3 min read·Apr 16, 2020----